
Méthodes d’ensemble#
The three most important things in real estate are: location, location, location. The three most important things in machine learning are: ensemble, ensemble, ensemble.
Adaptation libre d’un adage attribué à la communauté Kaggle
Les méthodes d’ensemble reposent sur une idée simple et puissante : combiner les prédictions de plusieurs modèles pour obtenir un modèle plus performant que chacun pris individuellement. Ce principe, parfois appelé sagesse des foules (wisdom of crowds), est l’un des résultats les plus robustes de l’apprentissage automatique. Ce chapitre couvre les grandes familles d’ensemble — bagging, boosting et stacking — ainsi que leurs implémentations les plus utilisées en pratique.
Introduction#
La sagesse des foules#
En 1906, le statisticien Francis Galton observa que la médiane des estimations d’un groupe de personnes cherchant à deviner le poids d’un boeuf était remarquablement proche de la valeur réelle — plus proche que la plupart des estimations individuelles, y compris celles des experts. Ce phénomène, formalisé bien plus tard sous le nom de sagesse des foules, repose sur deux conditions :
Diversité : les erreurs individuelles doivent être suffisamment différentes les unes des autres.
Indépendance : les estimations ne doivent pas être trop corrélées.
En apprentissage automatique, on retrouve exactement ces deux ingrédients. Un apprenant faible (weak learner) est un modèle dont la performance est à peine meilleure que le hasard. La théorie montre qu’en combinant un nombre suffisant d’apprenants faibles diversifiés, on peut obtenir un apprenant fort (strong learner) dont l’erreur est arbitrairement faible.
Définition 99 (Méthode d’ensemble)
Soit \(h_1, h_2, \ldots, h_M\) un ensemble de \(M\) modèles de base (base learners). Une méthode d’ensemble construit un modèle combiné \(H\) tel que
où \(\mathcal{C}\) est une fonction de combinaison (vote majoritaire, moyenne, moyenne pondérée, méta-modèle, etc.).
Remarque 95
La combinaison n’est bénéfique que si les modèles de base commettent des erreurs sur des exemples différents. Si tous les modèles se trompent sur les mêmes exemples, la combinaison n’apporte rien. C’est pourquoi les méthodes d’ensemble cherchent à maximiser la diversité entre les modèles de base.
Décomposition biais-variance#
Pour comprendre pourquoi les ensembles fonctionnent, il est utile de rappeler la décomposition biais-variance. Pour une fonction cible \(f\) et un modèle \(\hat{f}\) appris sur un échantillon d’entraînement, l’erreur quadratique moyenne en un point \(\mathbf{x}\) se décompose en
Le bagging réduit principalement la variance, tandis que le boosting réduit principalement le biais. C’est ce qui explique leurs comportements complémentaires.
Bagging#
Bootstrap Aggregating#
Le bagging (Bootstrap Aggregating), introduit par Leo Breiman en 1996, est la méthode d’ensemble la plus intuitive. L’idée est de créer de la diversité en entraînant chaque modèle de base sur un sous-ensemble différent des données, obtenu par échantillonnage bootstrap.
Définition 100 (Bootstrap)
Soit \(\mathcal{D} = \{(\mathbf{x}_1, y_1), \ldots, (\mathbf{x}_n, y_n)\}\) un jeu de données de taille \(n\). Un échantillon bootstrap \(\mathcal{D}^*\) est obtenu en tirant \(n\) observations avec remise dans \(\mathcal{D}\). En moyenne, chaque échantillon bootstrap contient environ \(1 - (1 - 1/n)^n \approx 1 - 1/e \approx 63{,}2\%\) des observations originales.
Définition 101 (Bagging)
Le bagging (Bootstrap Aggregating) procède comme suit :
Générer \(M\) échantillons bootstrap \(\mathcal{D}_1^*, \ldots, \mathcal{D}_M^*\) à partir de \(\mathcal{D}\).
Entraîner un modèle de base \(h_m\) sur chaque \(\mathcal{D}_m^*\).
Combiner les prédictions :
Régression : \(H(\mathbf{x}) = \frac{1}{M} \sum_{m=1}^M h_m(\mathbf{x})\) (moyenne)
Classification : \(H(\mathbf{x}) = \arg\max_c \sum_{m=1}^M \mathbb{1}[h_m(\mathbf{x}) = c]\) (vote majoritaire)
Réduction de la variance#
Le résultat fondamental du bagging est que la moyenne de modèles réduit la variance sans augmenter le biais.
Proposition 23 (Réduction de variance par moyennage)
Soient \(h_1, \ldots, h_M\) des modèles de base identiquement distribués, de variance \(\sigma^2\) et de corrélation par paires \(\rho\). La variance de la moyenne \(\bar{h} = \frac{1}{M}\sum_{m=1}^M h_m\) vaut
Proof. Calculons la variance de la moyenne :
Les termes diagonaux (\(m = m'\)) contribuent \(\frac{1}{M^2} \cdot M \cdot \sigma^2 = \frac{\sigma^2}{M}\).
Les termes hors diagonale (\(m \neq m'\)) contribuent \(\frac{1}{M^2} \cdot M(M-1) \cdot \rho\sigma^2\).
En sommant :
Lorsque \(M \to \infty\), la variance converge vers \(\rho\sigma^2\). La réduction est donc limitée par la corrélation \(\rho\) entre les modèles. C’est pourquoi il est crucial de maximiser la diversité (minimiser \(\rho\)).
Remarque 96
Si les modèles étaient parfaitement indépendants (\(\rho = 0\)), la variance décroîtrait en \(\sigma^2/M\). En pratique, les échantillons bootstrap sont corrélés (ils partagent environ 63 % des données), donc \(\rho > 0\) et la réduction de variance est plus modeste. Les forêts aléatoires, que nous verrons ensuite, introduisent une source supplémentaire de diversité pour réduire davantage \(\rho\).
Arbre seul — Accuracy : 0.820 (+/- 0.056)
Bagging (100) — Accuracy : 0.870 (+/- 0.065)
Forêts aléatoires#
Principe#
La forêt aléatoire (Random Forest), proposée par Breiman en 2001, est une extension du bagging qui ajoute une deuxième source de diversité : à chaque noeud de chaque arbre, seul un sous-ensemble aléatoire de features est considéré pour le split.
Définition 102 (Forêt aléatoire)
Une forêt aléatoire est un ensemble de \(M\) arbres de décision \(\{h_m\}_{m=1}^M\) construits comme suit :
Pour chaque arbre \(m\), tirer un échantillon bootstrap \(\mathcal{D}_m^*\) de taille \(n\).
À chaque noeud de l’arbre, sélectionner aléatoirement \(q\) features parmi les \(p\) disponibles, et choisir le meilleur split parmi ces \(q\) features uniquement.
Développer l’arbre sans élagage (profondeur maximale).
La prédiction est obtenue par vote majoritaire (classification) ou par moyenne (régression).
Les valeurs typiques de \(q\) sont \(q = \lfloor\sqrt{p}\rfloor\) pour la classification et \(q = \lfloor p/3 \rfloor\) pour la régression.
Remarque 97
La restriction du nombre de features candidates à chaque noeud réduit la corrélation \(\rho\) entre les arbres. Avec le bagging simple, tous les arbres tendent à utiliser les mêmes features dominantes et produisent des prédictions similaires. En limitant le choix à \(q \ll p\) features, on force les arbres à exploiter des aspects différents des données, ce qui diminue \(\rho\) et donc la variance de l’ensemble.
Score OOB#
Définition 103 (Score Out-of-Bag)
Chaque échantillon bootstrap \(\mathcal{D}_m^*\) omet environ 36,8 % des observations originales. Ces observations hors du sac (out-of-bag, OOB) constituent un jeu de validation naturel pour l’arbre \(h_m\). Le score OOB est calculé en prédisant chaque observation \(\mathbf{x}_i\) uniquement avec les arbres pour lesquels \(\mathbf{x}_i\) n’a pas été utilisée lors de l’entraînement :
Le score OOB fournit une estimation non biaisée de l’erreur de généralisation, sans nécessiter de jeu de validation séparé.
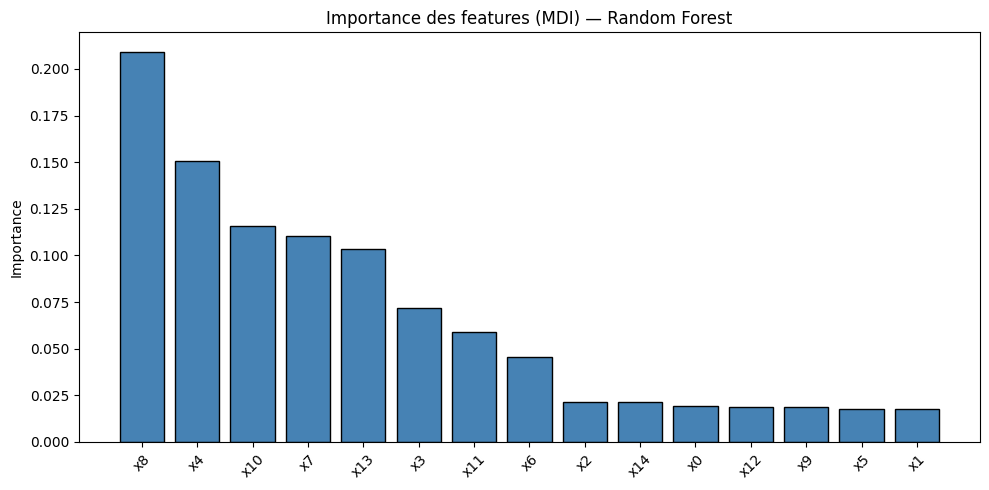
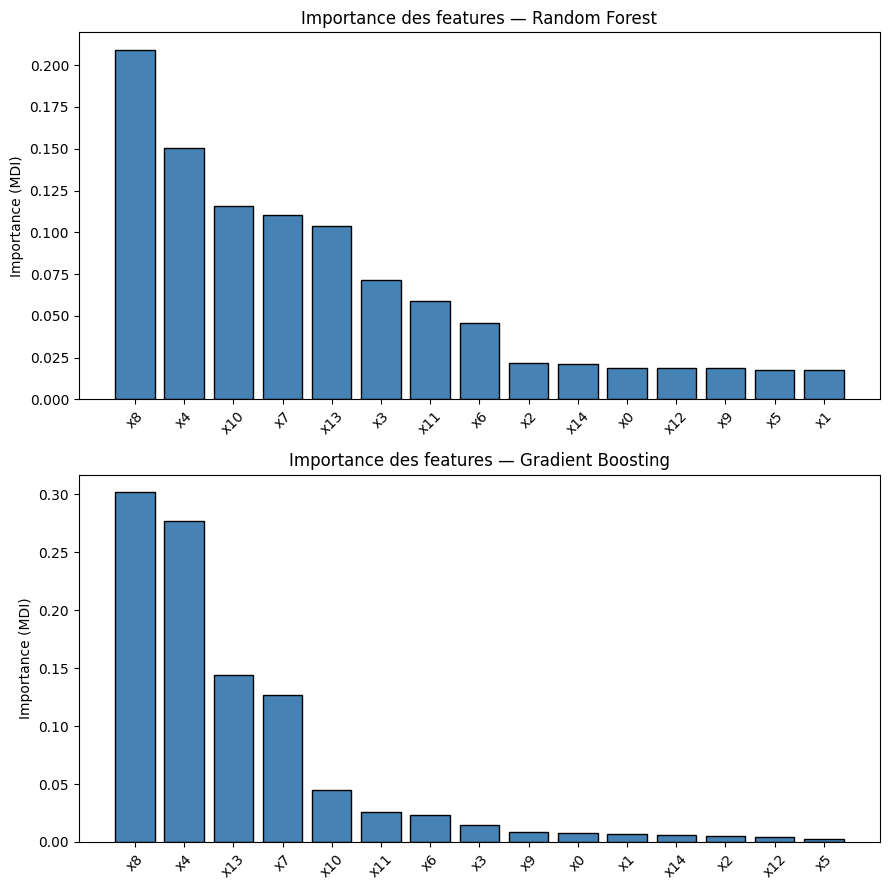
Importance des features#
Définition 104 (Importance par impureté (MDI))
L”importance par diminution d’impureté (Mean Decrease in Impurity, MDI) d’une feature \(j\) est la somme pondérée des diminutions d’impureté (Gini ou entropie) causées par les splits sur \(j\), moyennée sur tous les arbres :
où \(\mathcal{T}_m\) est l’ensemble des noeuds de l’arbre \(m\), \(v(t)\) est la feature utilisée au noeud \(t\), et \(\Delta I(t)\) est la diminution d’impureté au noeud \(t\).
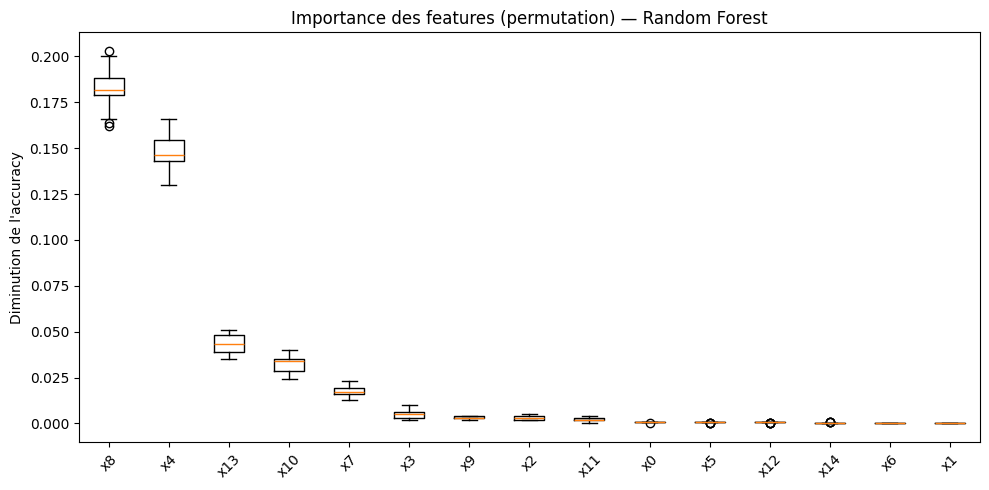
Remarque 98
L’importance MDI est biaisée en faveur des features à haute cardinalité (beaucoup de valeurs distinctes) et des features numériques. L’importance par permutation (Mean Decrease in Accuracy, MDA), qui mesure la perte de performance lorsqu’on permute aléatoirement les valeurs d’une feature, est un indicateur plus fiable mais plus coûteux à calculer.
Score OOB : 0.934
Boosting#
Principe#
Le boosting adopte une stratégie radicalement différente du bagging : au lieu d’entraîner les modèles de base en parallèle et de les moyenner, il les entraîne séquentiellement, chaque nouveau modèle se concentrant sur les erreurs commises par les précédents.
Définition 105 (Boosting)
Le boosting construit un ensemble additif de modèles de base :
où chaque \(h_m\) est ajusté pour corriger les erreurs résiduelles de \(H_{m-1}\), et \(\alpha_m\) est le poids (ou le taux d’apprentissage) associé au modèle \(m\).
Remarque 99
Le bagging réduit la variance en moyennant des modèles instables (arbres profonds). Le boosting réduit le biais en combinant des modèles très simples (arbres peu profonds, appelés stumps). En pratique, le boosting est plus susceptible de surapprendre si le nombre d’itérations est trop élevé ou si les données sont bruitées.
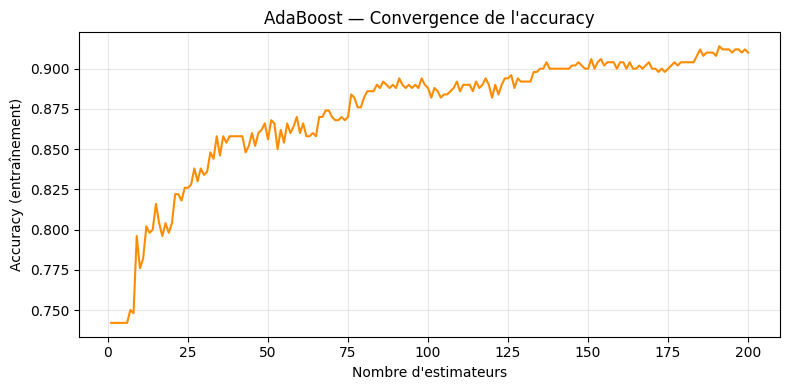
AdaBoost#
Algorithme#
L’algorithme AdaBoost (Adaptive Boosting), proposé par Freund et Schapire en 1997, est le premier algorithme de boosting pratiquement efficace. Il maintient une distribution de poids sur les exemples d’entraînement et augmente le poids des exemples mal classés à chaque itération.
Définition 106 (AdaBoost)
Soit \(\mathcal{D} = \{(\mathbf{x}_i, y_i)\}_{i=1}^n\) avec \(y_i \in \{-1, +1\}\).
Initialisation : \(w_i^{(1)} = 1/n\) pour tout \(i\).
Pour \(m = 1, \ldots, M\) :
Entraîner un apprenant faible \(h_m\) sur \(\mathcal{D}\) pondéré par \(\mathbf{w}^{(m)}\).
Calculer l’erreur pondérée :
\[\varepsilon_m = \sum_{i=1}^n w_i^{(m)} \mathbb{1}[h_m(\mathbf{x}_i) \neq y_i]\]Calculer le coefficient du modèle :
\[\alpha_m = \frac{1}{2} \ln\left(\frac{1 - \varepsilon_m}{\varepsilon_m}\right)\]Mettre à jour les poids :
\[w_i^{(m+1)} = \frac{w_i^{(m)} \exp\left(-\alpha_m y_i h_m(\mathbf{x}_i)\right)}{Z_m}\]où \(Z_m\) est un facteur de normalisation tel que \(\sum_i w_i^{(m+1)} = 1\).
Prédiction : \(H(\mathbf{x}) = \text{sign}\left(\sum_{m=1}^M \alpha_m h_m(\mathbf{x})\right)\)
Remarque 100
Le coefficient \(\alpha_m\) est d’autant plus grand que l’erreur \(\varepsilon_m\) est faible. Un classifieur parfait (\(\varepsilon_m = 0\)) reçoit un poids infini ; un classifieur aléatoire (\(\varepsilon_m = 0{,}5\)) reçoit un poids nul. Si \(\varepsilon_m > 0{,}5\), l’algorithme s’arrête (le classifieur est pire que le hasard).
La mise à jour des poids augmente le poids des exemples mal classés (car \(y_i h_m(\mathbf{x}_i) = -1\) pour un exemple mal classé, donc \(\exp(-\alpha_m \cdot (-1)) = \exp(\alpha_m) > 1\)) et diminue celui des exemples bien classés. Ainsi, le prochain classifieur se concentre sur les exemples difficiles.
Proposition 24 (Borne sur l’erreur d’entraînement d’AdaBoost)
L’erreur d’entraînement de l’ensemble AdaBoost après \(M\) itérations est bornée par
Si chaque classifieur faible atteint \(\varepsilon_m \leq 1/2 - \gamma\) pour un \(\gamma > 0\), alors l’erreur d’entraînement décroît exponentiellement en \(\exp(-2M\gamma^2)\).
AdaBoost — Accuracy : 0.800 (+/- 0.044)
Gradient Boosting#
Descente de gradient dans l’espace des fonctions#
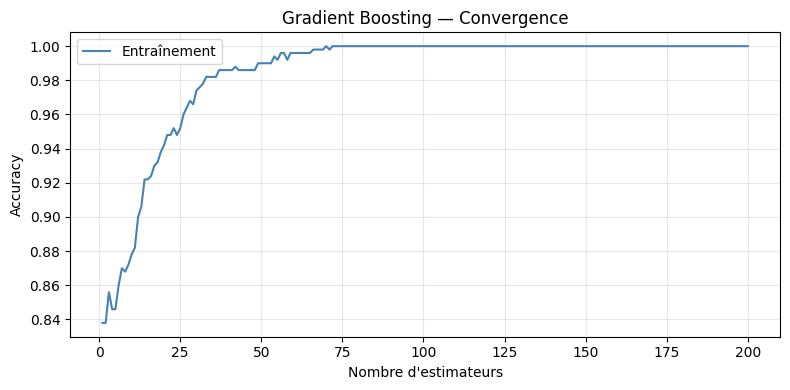
Le Gradient Boosting, formalisé par Friedman en 2001, généralise le boosting à n’importe quelle fonction de perte différentiable. Au lieu de manipuler des poids sur les exemples comme AdaBoost, il ajuste chaque nouveau modèle sur les résidus négatifs du gradient de la fonction de perte.
Définition 107 (Gradient Boosting)
Soit \(L(y, F(\mathbf{x}))\) une fonction de perte différentiable. Le Gradient Boosting construit un modèle additif \(F_M(\mathbf{x}) = \sum_{m=0}^M \eta \cdot h_m(\mathbf{x})\) comme suit :
Initialisation : \(F_0(\mathbf{x}) = \arg\min_c \sum_{i=1}^n L(y_i, c)\)
Pour \(m = 1, \ldots, M\) :
Calculer les pseudo-résidus (gradient négatif) :
\[r_{im} = -\left[\frac{\partial L(y_i, F(\mathbf{x}_i))}{\partial F(\mathbf{x}_i)}\right]_{F = F_{m-1}}\]Ajuster un modèle de base \(h_m\) sur les pseudo-résidus : \(h_m \leftarrow \text{fit}(\mathbf{X}, \mathbf{r}_m)\).
Mettre à jour :
\[F_m(\mathbf{x}) = F_{m-1}(\mathbf{x}) + \eta \cdot h_m(\mathbf{x})\]où \(\eta \in (0, 1]\) est le taux d’apprentissage (learning rate).
Remarque 101
L’interprétation est élégante : à chaque itération, on effectue un pas de descente de gradient, non pas dans l’espace des paramètres comme d’habitude, mais dans l”espace des fonctions. Le pseudo-résidu \(r_{im}\) indique la direction dans laquelle la prédiction pour \(\mathbf{x}_i\) devrait être ajustée pour réduire la perte. Le nouveau modèle \(h_m\) approxime cette direction.
Fonctions de perte#
Définition 108 (Fonctions de perte courantes)
Tâche |
Nom |
\(L(y, F)\) |
Pseudo-résidu \(r_i\) |
|---|---|---|---|
Régression |
Erreur quadratique |
\(\frac{1}{2}(y - F)^2\) |
\(y_i - F(\mathbf{x}_i)\) |
Régression |
Erreur absolue |
\(\lvert y - F \rvert\) |
\(\text{sign}(y_i - F(\mathbf{x}_i))\) |
Régression |
Huber |
Quadratique si \(\lvert r \rvert \leq \delta\), linéaire sinon |
Hybride |
Classification |
Log-loss (binaire) |
\(\ln(1 + e^{-yF})\) |
\(y_i - \sigma(F(\mathbf{x}_i))\) |
Pour la perte quadratique, les pseudo-résidus sont simplement les résidus ordinaires \(y_i - F_{m-1}(\mathbf{x}_i)\), ce qui donne une interprétation intuitive : chaque arbre prédit les erreurs des arbres précédents.
Remarque 102
Le taux d’apprentissage \(\eta\) (typiquement 0,01 à 0,3) joue un rôle de régularisation : un \(\eta\) faible nécessite plus d’arbres mais réduit l’overfitting. Il existe un compromis entre \(\eta\) et \(M\) : diminuer \(\eta\) d’un facteur 10 nécessite environ 10 fois plus d’arbres pour atteindre la même performance. En pratique, on fixe \(\eta\) petit et on utilise un early stopping pour déterminer \(M\).
Gradient Boosting — Accuracy : 0.898 (+/- 0.060)
Régularisation du Gradient Boosting#
Proposition 25 (Techniques de régularisation)
Le Gradient Boosting dispose de plusieurs leviers de régularisation :
Taux d’apprentissage \(\eta\) : réduit la contribution de chaque arbre.
Sous-échantillonnage (subsample) : chaque arbre est entraîné sur une fraction \(s < 1\) des données (sans remise). On parle alors de Stochastic Gradient Boosting.
Profondeur maximale (max_depth) : limite la complexité de chaque arbre (typiquement 3 à 8).
Nombre minimal d’exemples par feuille (min_samples_leaf).
Early stopping : arrêter l’entraînement lorsque la performance sur un jeu de validation cesse de s’améliorer.
XGBoost et LightGBM#
Les implémentations industrielles du gradient boosting ont considérablement amélioré la vitesse et les performances par rapport à l’implémentation de base de Scikit-learn.
XGBoost#
Définition 109 (XGBoost)
XGBoost (eXtreme Gradient Boosting, Chen & Guestrin, 2016) est une implémentation optimisée du gradient boosting qui introduit :
Régularisation L1 et L2 sur les poids des feuilles :
\[\Omega(h) = \gamma T + \frac{1}{2}\lambda \sum_{j=1}^T w_j^2 + \alpha \sum_{j=1}^T |w_j|\]où \(T\) est le nombre de feuilles et \(w_j\) est le poids de la feuille \(j\).
Approximation de Taylor au second ordre de la fonction de perte, utilisant à la fois le gradient \(g_i\) et le hessien \(h_i\) pour un choix de split plus précis.
Algorithme de split approché (approximate greedy algorithm) basé sur des quantiles pondérés, réduisant la complexité de \(O(n \cdot p)\) à \(O(n \cdot q)\) où \(q \ll n\) est le nombre de candidats.
Gestion native des valeurs manquantes : l’algorithme apprend automatiquement la direction optimale pour les valeurs manquantes à chaque noeud.
LightGBM#
Définition 110 (LightGBM)
LightGBM (Light Gradient Boosting Machine, Ke et al., 2017) introduit deux innovations majeures :
GOSS (Gradient-based One-Side Sampling) : échantillonnage conservant tous les exemples à fort gradient (mal prédits) et sous-échantillonnant les exemples à faible gradient. Cela accélère l’entraînement sans perte significative de performance.
EFB (Exclusive Feature Bundling) : regroupement des features mutuellement exclusives (rarement non nulles simultanément) pour réduire la dimensionnalité effective.
Croissance par feuille (leaf-wise) au lieu de la croissance par niveau (level-wise) : LightGBM développe la feuille qui réduit le plus la perte, ce qui produit des arbres asymétriques mais plus efficaces.
Remarque 103
En résumé, les différences principales sont :
Aspect |
XGBoost |
LightGBM |
|---|---|---|
Stratégie de croissance |
Par niveau (défaut) |
Par feuille |
Vitesse |
Rapide |
Très rapide |
Gestion des catégorielles |
Nécessite encodage |
Support natif |
Parallélisme |
Par feature |
Par données |
Mémoire |
Modérée |
Faible |
En pratique, LightGBM est souvent préféré pour les grands jeux de données en raison de sa vitesse supérieure. XGBoost reste un choix solide et très populaire, notamment dans les compétitions Kaggle.
HistGradientBoosting — Accuracy : 0.938 (+/- 0.027)
Remarque 104
Scikit-learn propose HistGradientBoostingClassifier et HistGradientBoostingRegressor, directement inspirés de LightGBM. Ces estimateurs utilisent des histogrammes pour discrétiser les features, ce qui les rend bien plus rapides que GradientBoostingClassifier sur les grands jeux de données (\(n > 10\,000\)). Ils supportent également les valeurs manquantes nativement.
XGBoost — Accuracy : 0.931 (+/- 0.028)
LightGBM — Accuracy : 0.936 (+/- 0.031)
Stacking#
Principe du méta-apprentissage#
Le stacking (stacked generalization), introduit par Wolpert en 1992, combine des modèles hétérogènes à l’aide d’un méta-modèle qui apprend à optimiser la combinaison.
Définition 111 (Stacking)
Le stacking à deux niveaux procède comme suit :
Niveau 0 (modèles de base) : Soit \(h_1, \ldots, h_M\) des modèles de base de types éventuellement différents. On obtient les prédictions de chaque modèle par validation croisée :
où \(h_m^{(-i)}\) désigne le modèle \(h_m\) entraîné sur les données excluant \(\mathbf{x}_i\) (en pratique, via \(k\)-fold CV).
Niveau 1 (méta-modèle) : On construit une matrice de méta-features \(\mathbf{Z} \in \mathbb{R}^{n \times M}\) où \(Z_{im} = \hat{y}_i^{(m)}\), puis on entraîne un méta-modèle \(g\) :
Le méta-modèle apprend les forces et faiblesses de chaque modèle de base et pondère leurs contributions de manière optimale.
Remarque 105
Il est crucial que les prédictions du niveau 0 soient obtenues par validation croisée et non par prédiction sur les données d’entraînement, sinon le méta-modèle apprend simplement à faire confiance aux modèles qui surapprennent le plus. Le méta-modèle est généralement un modèle simple (régression logistique, régression linéaire) pour éviter le surajustement au niveau 1.
Stacking — Accuracy : 0.930 (+/- 0.028)
rf — Accuracy : 0.882 (+/- 0.031)
gb — Accuracy : 0.888 (+/- 0.044)
svc — Accuracy : 0.936 (+/- 0.027)
Comparaison pratique#
Quand utiliser quoi ?#
Proposition 26 (Guide de choix des méthodes d’ensemble)
Méthode |
Forces |
Faiblesses |
Usage typique |
|---|---|---|---|
Bagging |
Réduit la variance, parallélisable |
Ne réduit pas le biais |
Modèles instables (arbres profonds) |
Random Forest |
Robuste, peu d’hyperparamètres, OOB |
Moins performant que le boosting sur données tabulaires |
Référence (baseline) solide |
AdaBoost |
Simple, borne théorique |
Sensible au bruit, pas de contrôle de la perte |
Classification binaire |
Gradient Boosting |
Flexible (choix de la perte), performant |
Lent, séquentiel, hyperparamètres à régler |
Données tabulaires, compétitions |
XGBoost / LightGBM |
Très rapide, régularisé, gère les NaN |
Plus d’hyperparamètres |
Production, grands jeux de données |
Stacking |
Combine des modèles hétérogènes |
Coûteux, risque d’overfitting |
Compétitions, derniers % de performance |
Comparaison sur un jeu de données#
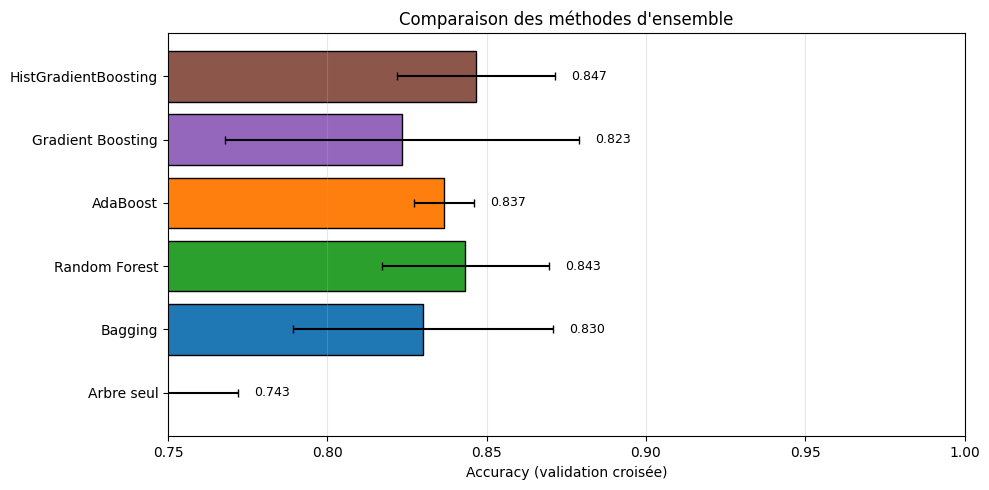
Arbre seul — Accuracy : 0.743 (+/- 0.029) [0.01s]
Bagging — Accuracy : 0.830 (+/- 0.041) [0.22s]
Random Forest — Accuracy : 0.843 (+/- 0.026) [0.13s]
AdaBoost — Accuracy : 0.837 (+/- 0.009) [0.15s]
Gradient Boosting — Accuracy : 0.823 (+/- 0.056) [0.15s]
HistGradientBoosting — Accuracy : 0.847 (+/- 0.025) [0.12s]
Résumé#
Les méthodes d’ensemble sont parmi les outils les plus puissants de l’apprentissage automatique. Elles reposent sur le principe fondamental que la combinaison de modèles diversifiés surpasse les modèles individuels.
Famille |
Principe |
Réduit |
Exemples |
|---|---|---|---|
Bagging |
Moyennage de modèles entraînés sur des bootstraps |
Variance |
Random Forest |
Boosting |
Correction séquentielle des erreurs |
Biais |
AdaBoost, Gradient Boosting, XGBoost, LightGBM |
Stacking |
Méta-modèle sur les prédictions de base |
Biais + Variance |
StackingClassifier |
Remarque 106
Sur les données tabulaires, les méthodes de gradient boosting (XGBoost, LightGBM, CatBoost) dominent les benchmarks et les compétitions depuis des années. La forêt aléatoire reste un excellent choix par défaut en raison de sa robustesse et de sa simplicité. Le stacking permet de grappiller les derniers points de performance, au prix d’une complexité accrue. Enfin, il est crucial de rappeler que le choix du modèle importe souvent moins que la qualité des données et du prétraitement : un gradient boosting sur des features mal construites sera surpassé par un simple arbre sur des features bien conçues.